
- Old Bailey Online
197,000 trials - Hathi Trust
Ten million books - Project Gutenberg
45,000 ebooks - Manuscriptorium
Five million digital images of manuscripts

Cannot make assumptions about the frame of reference.
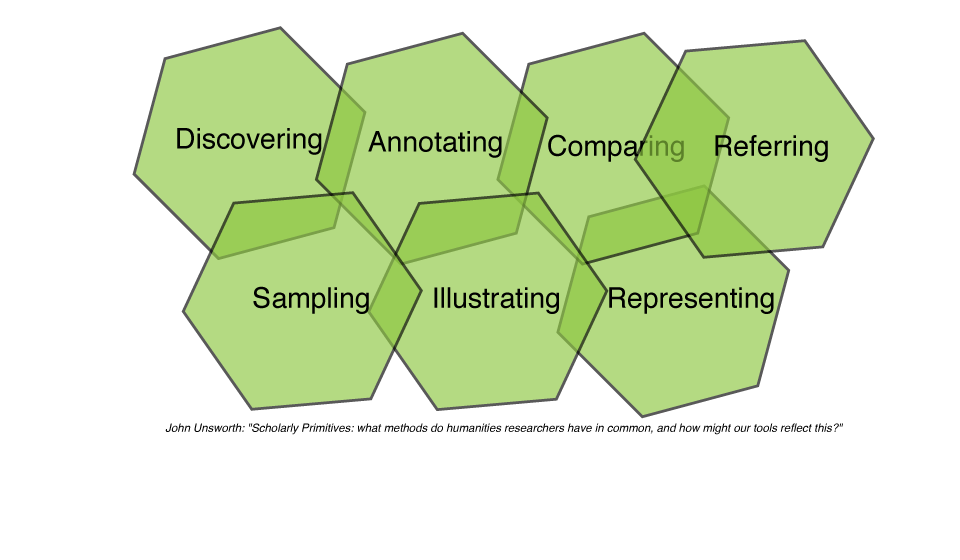

Hidden Knowledge
- Questions requiring interpretation of the text
- Questions not answered by a single document
- References to other resources



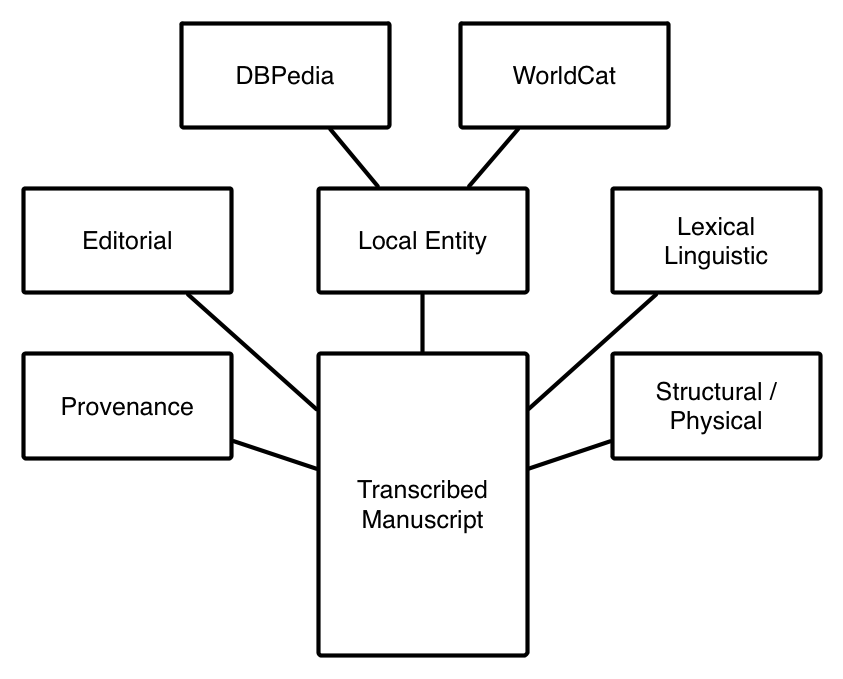
Can we put some historical documents into a package that is linked and marked up for the purpose of:
- training
- translating
- mining
- reading
Different content—Different markup
How to make it traceable?
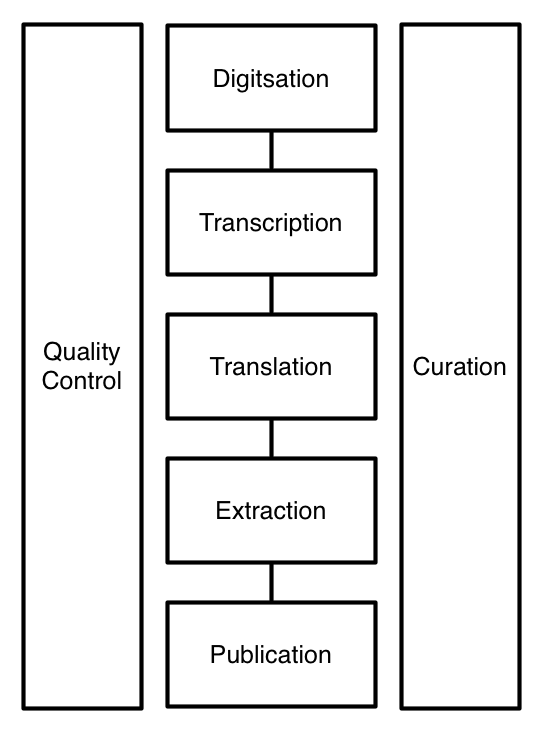
Workflows
- Best Practices for Publishing Multilingual Linked Open Data
- Multidimensional Quality Metrics (MQM) Definition
- CLARIN CMDI
- D2ME Open Workflows
- Onto-Lexica
- Linked Data in Linguistics: Representing and Connecting Language Data and Language Metadata
Chiarcos, Nordhoff, Hellmann (Eds.)